Making the move to machine learning predictive models
For many retailers, AI & machine learning is transforming the way they optimise their business. Those which stick to traditional tools lack the ability to make full-use of their growing datasets and risk being left behind. Machine learning helps ensure you make the best possible decisions – whether that be the right products for your customers, ensuring you have the right stores in the right place or optimising your customer marketing.
Recently, machine learning has been adopted into Javelin Group’s “Shape of Chain” methodology to help drive our predictive models for evaluating existing store performance and informing store portfolio optimisation. It has helped improve the accuracy of our strategic recommendations to businesses, however many retailers still struggle moving to machine learning tools.
5 reasons why retailers do not adopt AI:
1) Awareness – “What is it?”, “What’s the value to my business?”
2) Skillsets – “How do I get trained data scientists in my team?”
3) Implementation – “Which software/tool should I use?”
4) Cost – “It’s too expensive to implement”
5) Complexity – “I can’t understand the model or explain it to my stakeholders”
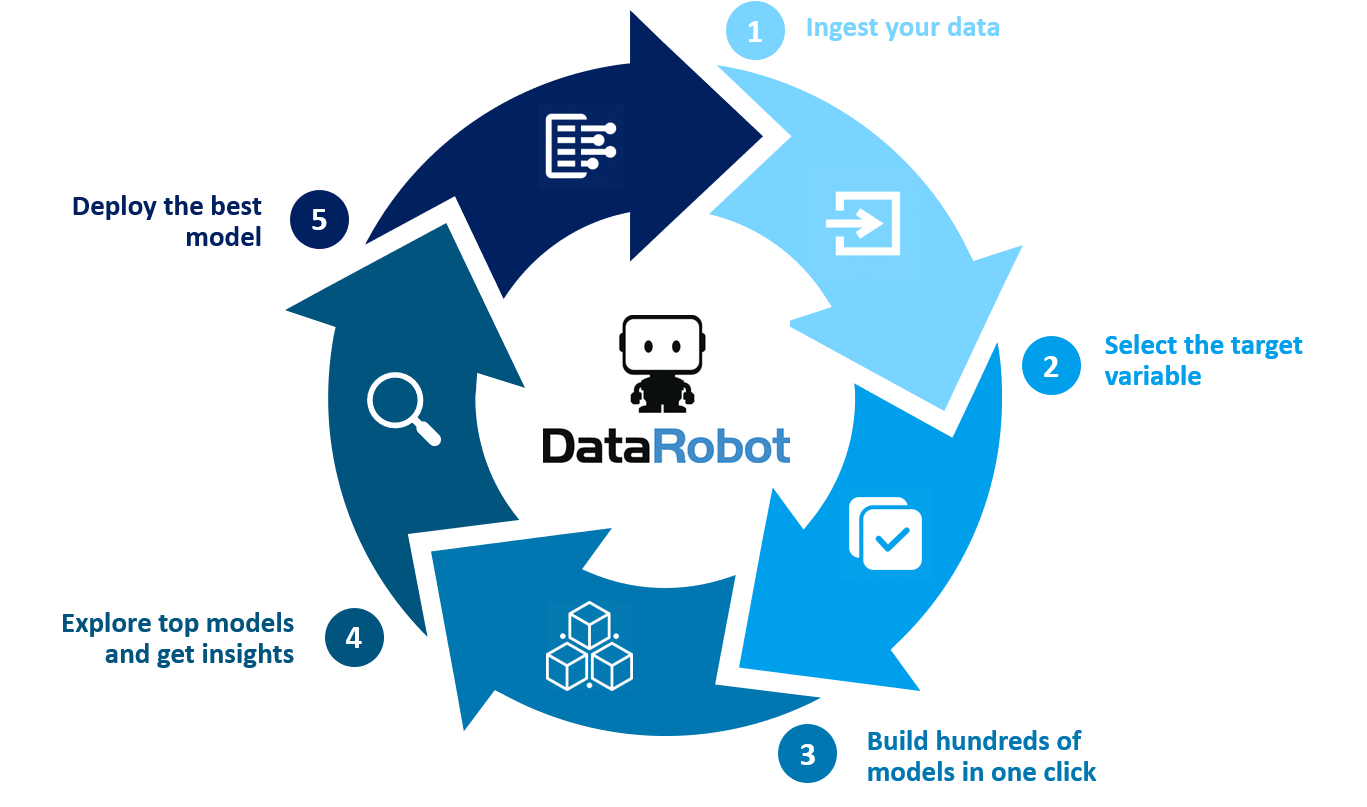
Adopting machine learning tools can be a daunting task and it may be tricky for your in-house data scientists writing lines of code to confidently tell you what is driving their predictive models. At Javelin Group, we’ve added to our existing software stack by partnering with DataRobot, a leading machine learning (AI) platform which boasts clients such as Kroger in the USA and Carrefour in France.

DataRobot is mostly code-free and very user friendly, with its strength in its ability to convey complex models in easy to understand ways and effectively unpacking the “black box” of machine learning. It’s also cost effective and flexible to deploy with the ability to connect via APIs (Python & Java code supported) and directly into Alteryx (version 4 available on the gallery here).
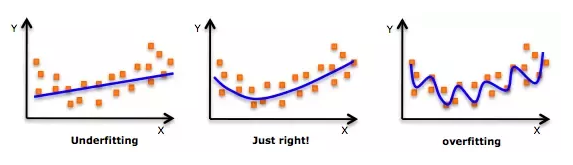
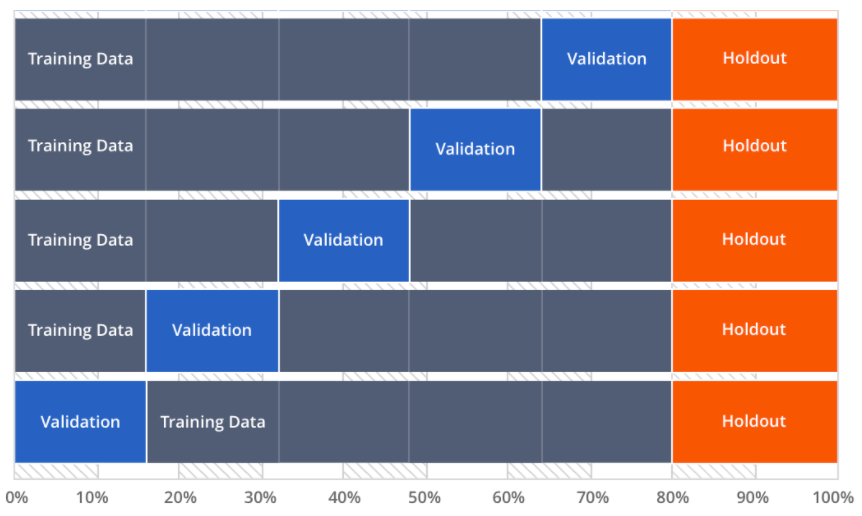
Machine learning solves for several challenges in building accurate & reliable models, one of which is getting the right level of “fit”. An under-fitted model is too simple, whilst an over-fitted one looks great, but will likely perform poorly when applied outside of the trained dataset. It does this through “cross validation” which partitions the dataset (for instance into 5 pieces). Building five models instead of one and exploring how the 80% of the “trained” data predicts the 20% “tested” data helps understand the true performance, selecting the right model and calibrating it appropriately. DataRobot also goes one step further and creates a “holdout” dataset. As cross validation models have “seen” the tested data in choosing the best model, the holdout gives you a final model accuracy based on predictions of data not included in the model build. This process can be time-consuming and fiddly, but DataRobot will run this entire process for you on hundreds of different model types at a touch of a button.
Simply put, machine learning (and AI) doesn’t need to be complex or challenging and making the move will bring with it significant profit potential. But as with the risk of putting data in the wrong hands, the same applies to predictive modelling, and so ensuring you have the right skills and tools is very important. DataRobot has been built with best practice data science in mind, so you don’t need to worry about building an over-fitted model or trying and work out if that random forest model will outperform an elastic net regressor.
If you’re interested in learning more about how Javelin Group and DataRobot can help you with your business problems please get in touch with Jon.Tarsey@JavelinGroup.com